
Parte 3. Controlando la ejecución de programas¶
Se siguen perfilando los detalles del funcionamiento del robot. En la última reunión del consorcio se presentó un conjunto de simuladores que nos van a permitir probar el funcionamiento de nuestra aplicación con bastante realismo:
- Un simulador de posicionamiento, que genera elementos de una secuencia de posiciones a intervalos aleatorios de tiempo. Sin pérdida de generalidad, las posiciones tienen una única dimensión; es decir, se supone que el robot se mueve en una línea representada por caracteres ASCII en el rango ‘A’..’Z’, siendo la distancia recorrida entre dos puntos X e Y (es decir, el área explorada), el valor absoluto de la diferencia entre los valores ASCII que representan ambos puntos, |X–Y|.
- Un simulador de un sensor de CO2, que genera caracteres ASCII en el rango ‘0’..’5’. El valor ‘0’ indica la ausencia de CO2, mientras que el valor ‘5’ indica el nivel máximo de CO2.
- Un simulador de un sensor de humedad, que genera caracteres ASCII en el rango ‘a’..’f’. El valor ‘a’ indica la ausencia de agua, mientras que el valor ‘f’ indica el nivel máximo de humedad, que corresponde a la máxima probabilidad de vida.
El equipo de bioquímicos que trabaja en el consorcio ha considerado que a partir de las medidas conjuntas de CO2 y humedad se puede determinar con bastante fiabilidad la probabilidad de vida en una zona. En el prototipo de MCPV deberemos trabajar con estos dos sensores y la localización.
Es importante señalar que los sensores y el posicionamiento son eventos asíncronos, es decir, se pueden producir en cualquier momento, generando una secuencia entrelazada de datos de los tres sensores. Por ejemplo, si el robot se ha movido de la posición A a la posición C, podría entregar una secuencia como esta:
A0de00B3c5C ...
Más adelante el equipo de bioquímicos nos proporcionará la fórmula para interpretar las probabilidades de vida a partir de una secuencia entrelazada.
Actividad 3.1. Cómo ejecutar los simuladores simultáneamente en Linux¶
Dedicación estimada: 45 minutos¶
De la descripción del proyecto deducimos que para probar el funcionamiento del módulo deberemos ejecutar los simuladores simultáneamente. Pero, ¿nos permitirá el shell de Linux ejecutar más de un programa a la vez?
Ya tenemos alguna práctica con el manejo del shell de Linux y conocemos parte de sus posibilidades para el manejo de programas. El shell nos permite hacer muchas más cosas.
Qué hay que hacer¶
Experimenta con el shell haciendo que ejecute las órdenes siguientes, tratando de anticipar su efecto y explorando en el manual del
bashen caso necesario.(1) sleep 5 ; (2) sleep 5 & (3) sleep 5 ; date (4) sleep 5 & date (5) (sleep 5; date) & (6) (sleep 5; date) & date
Ya has visto las posibilidades que ofrece el shell en cuanto a cómo ejecutar los programas. Habrás observado que, además de la ejecución secuencial (programa a programa) que habíamos manejado hasta ahora, el shell permite continuar con la ejecución de programas sin que finalice el anterior. Esta forma de ejecución se denomina concurrente (o en background en la jerga de los shells). Prueba con los simuladores, ejecutándolos secuencial y concurrentemente, tanto con respecto a otros programas como entre ellos.
Tras estas pruebas, directamente puedes construir una orden
genera_secuenciaque genere la secuencia entrelazada de datos proporcionada concurrentemente por los simuladores a partir de la cual nuestro módulo podrá calcular las probabilidades de vida. Ten en cuenta quegenera_secuenciase limita a generar la secuencia entrelazada; de calcular las probabilidades de vida nos ocuparemos más adelante.
Resultados¶
La actividad se evalúa como correcta si la orden genera_secuencia produce por la salida estándar una secuencia entrelazada de los valores de la entrada de los tres simuladores.

Actividad 3.2. Pero ¿cómo lo hace el shell?¶
Dedicación estimada: 60 minutos¶
Un intérprete de comandos o shell, como el bash de Linux, no es más que un programa que nos permite manejar la ejecución de otros programas. Nos gustaría entender ahora cuáles son los mecanismos de Linux para manejar la ejecución secuencial o concurrente de los programas.
Ya conoces que un programa es un código ejecutable (o binario) que se obtiene tras el proceso de compilación y montaje de un código fuente y que incluye en el formato adecuado la información suficiente para que el programa se pueda ejecutar. Para empezar, vamos a explorar qué llamadas al sistema ofrece Linux para cargar y ejecutar un programa; en otras palabras, cómo construir un “shell” lo más básico posible para lanzar, por ejemplo, uno de nuestros simuladores.
Qué hay que hacer¶
Observa este programa Linux. Analiza el código, compílalo y ejecútalo. El programa toma como parámetro el nombre de un programa ejecutable (binario): puedes pasarle el nombre de uno de los simuladores, por ejemplo:
./ejecuta ./sim_CO2
Analiza cuidadosamente cómo se comporta. Explorando la llamada al sistema
execlpcon ayuda delmany la documentación sobre UNIX/Linux, y teniendo en cuenta lo que aprendiste en la Parte 1 sobre la ejecución de programas, trata de encontrar una explicación coherente del comportamiento de este código.Vamos a comprobar si has entendido bien lo que hace
execlp. Piensa en una nueva versión del programa del punto anterior con n argumentos, de forma que nos permita lanzar la ejecución de varios simuladores. Para ello, básicamente te limitas a llamar aexeclpdentro de un bucle, para cada argumento. ¿Obtendrás el comportamiento deseado? Si ya tienes una respuesta clara a esta pregunta, no necesitarás implementar esta prueba; si no, no te costará mucho implementarla y convencerte del resultado revisando la documentación.
Resultados¶
La actividad se evalúa como correcta si eres capaz de proporcionar una respuesta razonada a la pregunta planteada.
Actividad 3.3. Cómo Linux soporta la ejecución concurrente¶
Dedicación estimada: 2 horas y media¶
En la la Actividad 3.1 vimos que el shell es capaz de ejecutar programas tanto de forma secuencial como concurrente (en background). En la la Actividad 3.2 hemos comprobado que la llamada al sistema exec permite lanzar la ejecución de un programa, pero no proporciona ni secuencialidad ni concurrencia. Debemos seguir explorando para comprobar cómo un shell permite estas formas de ejecución.
Qué hay que hacer¶
Copia este programa Linux. Compílalo y ejecútalo. Con ayuda del
many, si es necesario, la bibliografía sobre Linux/UNIX, analiza el código y las llamadas al sistema del código involucradas en el manejo de procesos. Observa que el código contiene retardos aleatorios en algunos puntos. Repite las pruebas todo lo necesario para poder responder a las siguientes preguntas:- ¿Qué llamadas al sistema sobre procesos incluye el programa? ¿Qué hace cada una de ellas?
- ¿Cuántos procesos intervienen en este programa?
- ¿Cómo se identifica un proceso? ¿Qué identificadores tienen los procesos del programa?
- ¿Qué código ejecuta cada proceso?
- ¿A qué proceso pertenece la variable
dato? - Los valores asignados a la variable
dato, ¿dependen de la ejecución (es decir, de los retardos aleatorios) o son siempre los mismos?
El concepto de proceso es fundamental en Linux/UNIX. A partir de este experimento y de la exploración bibliográfica que necesites, debe quedarte perfectamente clara la diferencia entre proceso y programa.
Explora las órdenes
ps(con sus diferentes opciones) ytopdel shell, así como la herramienta monitor de la interfaz gráfica. Cualquiera de estos medios te permitirá conocer los atributos y la información que el sistema almacena de cada proceso. Elabora una lista, procurando describir cada uno de los atributos o campos de información lo más precisamente posible. Hay mucha bibliografía sobre procesos UNIX/Linux, y cualquier libro de texto te servirá como apoyo, aunque aquí tienes un resumen sobre el concepto de proceso.
Resultados¶
Evalúa lo que has aprendido con este test de autoevaluación. Repasa los conceptos en función de los resultados obtenidos.
Actividad 3.4. Nuestro propio shell para lanzar los simuladores¶
Dedicación estimada: 3 horas¶
Ya vimos que las llamadas al sistema exec se limitan a cargar un programa y saltar a su dirección de comienzo. Esto es muy restrictivo. Ya has podido comprobar que si diseñas un shell que ejecutase los programas solo con exec, no conseguirás más que ejecutar el primero y terminar.
También conocemos cómo se comporta la llamada al sistema fork(). La idea es: ¿podemos combinar fork y exec para lanzar la ejecución concurrente de nuestros simuladores? En esta actividad vamos a construir un shell sencillo en varias etapas.
Qué hay que hacer¶
Si has entendido bien las dos actividades anteriores, podrás abordar la construcción de un programa lanzador (nuestro shell sencillo) combinando los códigos que hemos usado en ambas. La llamada
fork()nos proporciona la forma de crear un flujo de ejecución (un proceso) nuevo. Podemos hacer que el proceso hijo ejecute el código del proceso padre, como en la Actividad 3.3, pero eso no nos interesa, ya que los simuladores tienen su propio código en un fichero ejecutable. Una llamada comoexeclppermite al proceso cargar un código ejecutable (¡y no salir de ahí!). La primera versión del lanzador que vas a construir,lanzador_0, debe ser capaz de ejecutar todos los programas que se le pasen como parámetros. No definiremos una especificación más precisa; simplemente consigue algo que funcione de la forma más sencilla posible. Pruébalanzador_0con los tres simuladores.Nota
Una diferencia entre un shell como el
bashy nuestrolanzador_0es que este no lee los nombres de los programas por la entrada estándar, sino que los toma como parámetros. Esto es para simplificar la construcción del programa y porque nuestro objetivo no es construir un shell típico, sino comprender cómo se consigue la ejecución concurrente o secuencial. Si estás interesado/a, te resultará muy sencillo obtener el código fuente de un shell, ya que es software libre. El libro de Rockhind explica cómo construir un shell completo paso a paso.¿Cómo se comporta tu
lanzador_0? ¿Lanza los programas como lo haría la ordenp1 ; p2 ; p3o como lo haría la ordenp1 & p2 & p3 &? Si has seguido el criterio de conseguir el lanzador más sencillo posible, apostaría a que has obtenido algo parecido a la segunda opción. En otras palabras, el lanzador no espera a que acabe la ejecución de cada uno de sus hijos, ejecutándose estos concurrentemente.Vamos a construir una segunda versión del lanzador,
lanzador_1, que ejecute los programas secuencialmente, escribiendo un mensaje por la salida estándar de error cuando acabe cada uno de los programas lanzados, y que termine cuando acabe de ejecutarse el último. Necesitamos para ello un mecanismo que permita que el proceso padre se quede esperando a que el hijo termine. No te será difícil encontrar ayuda en Internet e introducir la llamada al sistema correspondiente en el código delanzador_0para obtener la nueva versión.Nota
Ya que el programa está adquiriendo cierta complejidad, es importante que chequees sistemáticamente los diagnósticos que devuelven las llamadas al sistema utilizadas.
Actividad 3.5. El proceso y sus estados¶
Dedicación estimada: 45 minutos¶
Ya sabemos como crear procesos en Linux y cómo hacer que se comporten secuencial o concurrentemente. Es el momento de modelar el comportamiento de los procesos Linux antes de pasar a cuestiones más complejas.
Qué hay que hacer¶
- En la actividad anterior hemos identificado una condición por la que un proceso puede quedar a la espera de un evento. En este caso el evento se produce cuando uno de los hijos del proceso finaliza. El mecanismo es el mismo que Linux utiliza tratar la espera por una señal del reloj, que ya conocemos. De hecho, puedes consultar en la página sobre señales del man cuál es la señal concreta que se produce como consecuencia de la terminación de un hijo. También una operación de entrada/salida puede provocar que el proceso espere. Ya que todas estas situaciones son análogas, se recurre a modelar el comportamiento de los procesos Linux mediante un grafo de transiciones de estado, que te ayudará a comprender el camino que siguen tus procesos durante su ejecución.
Resultados¶
Evalúa lo que has aprendido con este test de autoevaluación. Repasa los conceptos en función de los resultados obtenidos.
Actividad 3.6. Un lanzador vigilante¶
Dedicación estimada: 5 horas¶
Con lanzador_0 podemos poner a trabajar concurrentemente a nuestros simuladores. Se nos ocurre que sería útil que el lanzador hiciera terminar las simulaciones en un tiempo establecido, sin depender de la duración de cada simulador, que así podría generar datos indefinidamente. Necesitamos para eso un lanzador vigilante que, además de ejecutar los programas, los haga terminar en un plazo de tiempo. Por ejemplo, cuando ejecutáramos:
./lanzador-vigilante 15 sim_pos sim_CO2 sim_H2O
todos los programas y el propio lanzador deberían acabar a los 15 segundos, si no han acabado antes.
Esta es la especificación del lanzador-vigilante que nos proponemos construir en esta actividad.
Qué hay que hacer¶
Primero debemos aprender cómo abortar la ejecución de un proceso (“matar” al proceso) desde el shell. Quizás en algunas ocasiones hayas necesitado terminar la ejecución de un programa utilizando la orden
kill(1). Consulta elmany prueba a lanzar uno de los simuladores en background y a matarlo conkill.Debemos conocer ahora qué llamada al sistema utiliza la orden
kill. No te será difícil localizarla en elman. No te sorprenderá descubrir que el mecanismo de señales también está involucrado en este tema.Vamos ahora con el diseño del programa. Fíjate primero que en
lanzador-vigilantelos programas se lanzan concurrentemente, como hacíalanzador_0, así que partiremos del código delanzador_0.c. En el diseño vamos a primar la sencillez y claridad con respecto a la eficiencia. Dividiremos la aplicación en dos programas. Uno de ellos será el sucesor delanzador_0y se parecerá bastante a él. El otro será el encargado de vigilar la ejecución de cada uno de los programas. Este último, al que llamaremoscontrolador, admitirá como argumentos un plazo de ejecución y el nombre de un programa a ejecutar. Va a ser el primero que construyas. Comienza por diseñar los casos de prueba para su verificación (fíjate que cumple un subconjunto de la especificación delanzador-vigilante).Nota
Este diseño es poco eficiente por doble motivo. Primero, porque utiliza dos programas en vez de uno. Segundo, porque lanzamos un reloj para controlar cada uno de los programas, cuando el plazo de tiempo es para todos el mismo. Como contrapartida ganamos modularidad y obtendremos un código que está preparado para soportar el lanzamiento de un conjunto de programas con diferentes plazos.
Una idea para construir
controladores la de lanzar el programa y utilizar la señalSIGALRMpara matarlo (recuerda que el comportamiento por defecto deSIGALRM, aunque parezca poco intuitivo, es hacer terminar al programa). Esta solución es bien sencilla, como puedes comprobar, pero no es válida, ya que el programa a controlar podría ignorar esta señal o cambiar su comportamiento instalando una función consignal(2), tal como hacíamos con algunos de nuestros relojes. Por lo tanto hay que ir a una solución más general que lance concurrentemente con el programa a vigilar un reloj que cuente el plazo. Así, si ejecutamos:./controlador 15 ./sim_pos
Se creará el siguiente esquema de procesos:

En el esquema, las flechas indican la relación es padre de entre procesos. Construye
controladorpara que, de acuerdo a este esquema, lance la ejecución del programa que se le pasa como segundo argumento y un reloj que cuente el plazo de tiempo especificado como primer argumento. Cuando finalice el primero de los dos procesos hijos, el padre matará al otro. Verifica su funcionamiento con los simuladores.Fíjate que, gracias al diseño modular que estamos siguiendo, con ayuda el shell casi podríamos ahorrarnos el resto del trabajo. Prueba esto:
./controlador 15 ./sim_pos & ./controlador 15 ./sim_CO2 & ./controlador 15 ./sim_H2O
¡Es casi equivalente a lo que pretendemos! Cuando se ejecuta esta orden, el esquema de procesos es el siguiente:
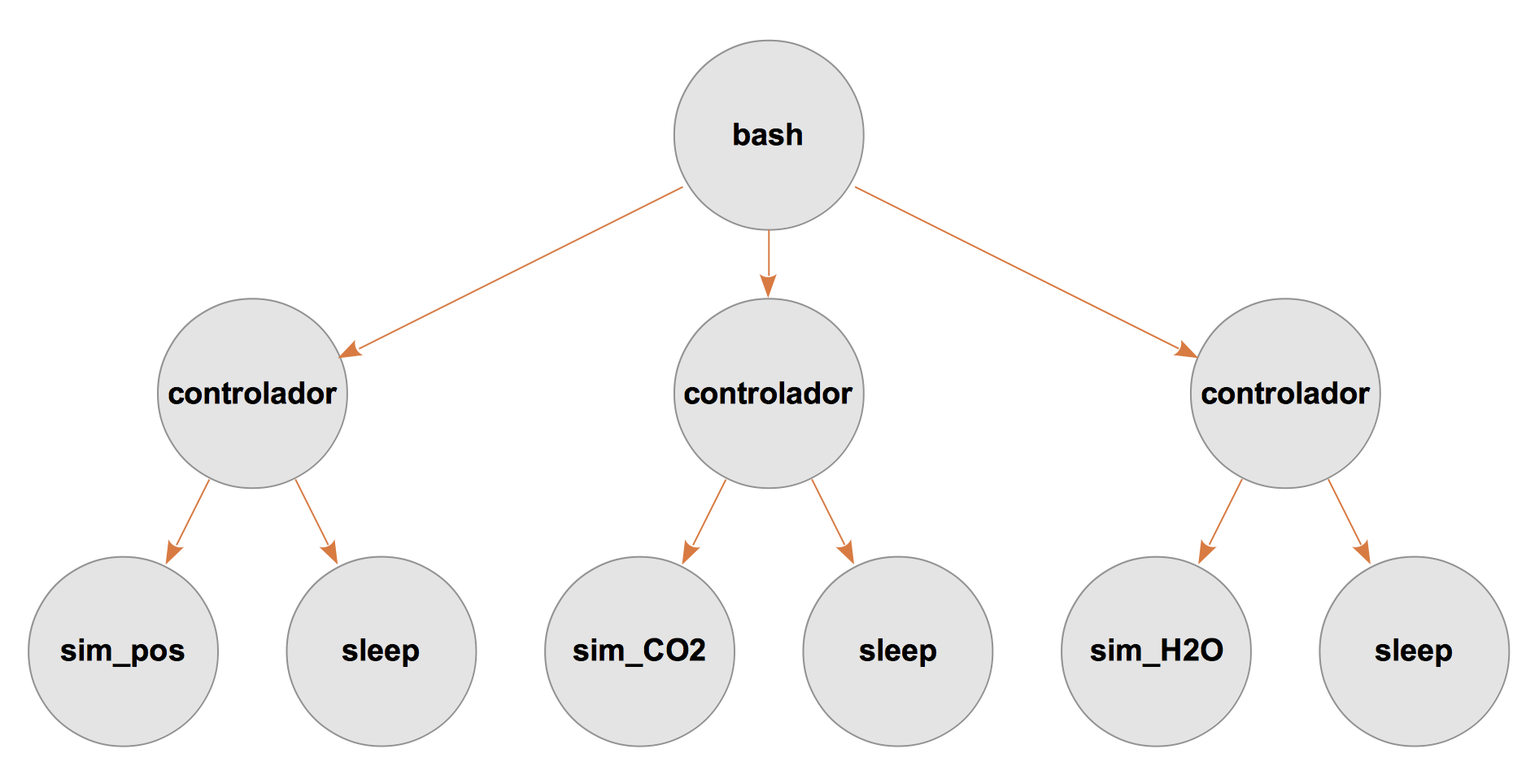
Finalmente, vamos a abordar el diseño de
lanzador-vigilantea partir delanzador_0. Fíjate que el esquema es como el de la figura anterior, salvo que ahora el proceso padre serálanzador-vigilante. Completa los casos de prueba, desarrollalanzador-vigilantede forma que delegue en ``controlador `` la ejecución y el control de cada programa, y verifica su funcionamiento.Nota
Si lanzas
lanzador-vigilanteen background (o si abres una segunda ventana del terminal), puedes ir comprobando el estado de los procesos conps a. Si todo está bien construido, no deberían quedar procesos zombies. Podrás observar la existencia temporal de zombies si metes un retardo largo antes de esperar por los hijos.
Resultados¶
La actividad se evalúa como correcta si has construido el programa modularmente como se propone y se comporta según lo especificado.
Actividad 3.7. Cómo Linux controla tantos procesos¶
Dedicación estimada: 3 horas¶
Sin duda, Linux requiere un gran esfuerzo de gestión para controlar la cantidad de procesos que se ejecutan concurrentemente, de forma que pueda coordinar el uso de los recursos del sistema por los procesos. En esta actividad exploraremos cómo lo hace y cómo lo percibe el usuario y el programador.
Qué hay que hacer:¶
- Echa un vistazo a los procesos que tu sistema Linux está ejecutando en este momento. Puedes verlo en el terminal con
ps auxlotop, o con el monitor del sistema en la interfaz gráfica. Con ayuda delman, trata de identificar qué tipo de información proporciona el sistema sobre qué recursos consumen los procesos, anotándolo en una lista. - En una actividad previa hemos conocido a grandes rasgos el modelo de procesos UNIX/Linux (y de la mayoría de los sistemas operativos multiprogramados) basado en la definición de un conjunto de estados y un grafo de transición de estados. Este modelo explica la dinámica de un proceso desde su propio punto de vista. Sin embargo, cuando el proceso se ve obligado a convivir con la cantidad de procesos que has observado, surgen muchas cuestiones, por ejemplo: ¿cómo puede haber más procesos que unidades de proceso (CPUs, procesadores, cores o como queramos llamarlas)? ¿qué ocurre si estoy listo para ejecución y no hay ninguna CPU libre? ¿cómo recuerda el sistema mi contexto cuando entro a ejecución después de un rato fuera? En resumen: ¿cómo gestiona Linux la concurrencia de procesos? Necesitamos ampliar el modelo de procesos para responder a estas cuestiones.
- Ahora que conoces un modelo de gestión de procesos, considera tres procesos en la cola de Preparados de un sistema Linux con una CPU libre. Supondremos que el proceso A, que está primero en la cola, va a necesitar 0,1 segundos de tiempo de CPU para terminar. El proceso B, en cambio, solo necesitará 0,01 segundos de CPU para acabar, y el proceso C, último en la cola, 0,02 segundos. El sistema operativo debe planificar el orden en que estos procesos utilizan el recurso CPU ¿En qué criterios debe basarse tal decisión? Parece que estos criterios deberían estar relacionados con el objetivo de maximizar la satisfacción de los procesos (o de sus propietarios). Por ejemplo, minimizar el tiempo de respuesta medio, es decir, el tiempo que esperan los procesos en la cola de preparados antes de entrar a la CPU, podría ser uno de los criterios a seguir. Establecido esto, debemos encontrar una estrategia adecuada para cumplir el criterio, por ejemplo: elegir el proceso según un orden FIFO. ¿Te parece la FIFO una estrategia adecuada para el criterio del tiempo de respuesta? ¿Serías capaz de encontrar una estrategia mejor para este objetivo? Explora estrategias alternativas y calcula los tiempos medios de respuesta obtenidos con la que te parezca mejor y con la FIFO. Te será útil representar en un cronograma los tiempos de los procesos en cada estado durante su ejecución.
- El criterio tiempo de respuesta parece bastante razonable e intuitivo, pero no es el único posible. Por ejemplo, puede haber procesos con más “prisa” que otros, como los de tiempo real. Finalmente, el sistema operativo tiene sus propias restricciones para implementar las políticas: al fin y al cabo el esfuerzo del sistema para gestionar adecuadamente los procesos de acuerdo a los objetivos marcados también consume recursos de CPU. Consulta este documento sobre la planificación de procesos, que es aplicable a Linux y en general a cualquier sistema operativo.
Resultados¶
Evalúa lo que has aprendido en esta actividad con este test de autoevaluación. Repasa los conceptos en función de los resultados obtenidos.
