
Planificación de procesos¶
Una parte fundamental de la tarea de gestión de procesos que hace el sistema operativo es la de la planificar la utilización de los recursos de ejecución por los procesos. Fundamentalmente, el sistema tiene que aplicar criterios para decidir (a) qué proceso elige para ocupar la CPU, y (b) cuándo aplica el criterio anterior. Adicionalmente, si tenemos múltiples CPUs, el sistema debería planificar (c) qué CPU ocupa un proceso, aunque no nos ocuparemos aquí de este tema, asumiendo que el sistema tiene una única CPU. Esto no supone pérdida de generalidad en las técnicas que vamos a explorar.
Tal como acabamos de definir la planificación de procesos, se la denomina planificación a corto plazo, en el sentido de que la planificación se realiza para aplicarla inmediatamente. La planificación a corto plazo la ejecuta una función interna del sistema operativo, el scheduler, dentro de la secuencia de acciones del cambio de contexto. Sin embargo, los sistemas operativos como Linux incluyen formas de planificación indirecta o de plazo más largo. Por ejemplo, ya veremos que los sistemas toman la prioridad de un proceso como criterio para la planificación, y que la prioridad puede variar a lo largo de la ejecución del proceso. El valor inicial de la prioridad se establece en el momento de lanzar el proceso. El sistema, y hasta cierto punto el usuario, influyen en el la planificación durante la vida del proceso estableciendo un valor más alto o más bajo para esta prioridad inicial. Este tipo de planificación diferida se denomina planificación a largo plazo. En Linux el usuario dispone de una orden nice(1) para ajustar la prioridad inicial (que el proceso nunca rebasará) en el momento de ejecutar el programa, aunque solo el administrador (usuario root) puede usarla para elevar la prioridad de un proceso. La orden nice se suele utilizar para ejecutar en background procesos de cálculo intensivo que no necesitan terminar en un plazo de tiempo.
También podemos considerar formas de planificación a medio plazo. Por ejemplo, Linux incluye una llamada setpriority que, además de usarla el shell para implementar nice(1), permite modificar la prioridad durante la ejecución del proceso en relación a las de otros procesos (por ejemplo del mismo usuario). De nuevo, su ámbito de aplicación está relacionado con los procesos de cálculo intensivo o paralelo, que quedan fuera de los objetivos del curso. Otra forma de planificación a medio plazo la realiza el propio sistema operativo cuando decide que un proceso abandone la memoria, aun sin finalizar (por ejemplo cuando hay demasiados procesos y la memoria escasea. Mientras no se libere memoria suficiente el proceso no va a ser considerado por el scheduler. Fíjate que este mecanismo implica desdoblar los estados Preparado y Bloqueado en Preparado en memoria y Preparado fuera de memoria por una parte, y Bloqueado en memoria y Bloqueado fuera de memoria por otra, ampliando el grafo de transición de estados (si te apetece, puedes dibujarlo y definir las nuevas transiciones como ejercicio).
Nota
La memoria RAM suele ser un recurso crítico que se convierte en escaso a medida que nuestro ordenador envejece. Esto se debe a que los sistemas operativos utilizan memoria virtual para permitir ejecutar cualquier número de programas y de cualquier tamaño, aunque no quepan todos juntos en la RAM. El sistema utiliza el disco (la denominada área de swap) como respaldo para el exceso de memoria necesaria. Seguramente habrás notado que cuando tu ordenador está muy cargado ejecuta los programas con mucha lentitud. La culpa no es del procesador, sino de la falta de memoria RAM y de la relativamente bajísima velocidad del disco. El sistema de memoria virtual permite cargar cuantos programas quieras a costa de repartir la escasa memoria física entre todos, de forma que tiene que andar sacando y metiendo procesos (mejor dicho, partes de su contexto) entre la RAM y el disco. En esta situación, denominada thrashing, la CPU está prácticamente sin trabajo, esperando a que el sistema de DMA finalice las continuas y lentas transferencias. Las memorias flash (impropiamente llamadas discos SSD) alivian un poco este problema.
Para identificar adecuadamente las estrategias, o políticas de planificación, que aplicará el scheduler, es necesario primero tener claros los objetivos que se persiguen con la planificación, fundamentalmente relacionados con la satisfacción de los procesos.
Criterios para la planificación¶
Ya sabemos que el tiempo de respuesta es un criterio relevante, en cuanto a que coincide con un aspecto de la calidad de servicio perfectamente identificable por los usuarios, anque no el único:
Tiempo de respuesta o latencia, tr. Tiempo desde que un proceso entra en el estado de preparado (porque se crea o porque se desbloquea) hasta que entra en ejecución.
Tiempo de finalización, tf. Tiempo desde que se solicita la ejecución de un programa hasta que ésta finaliza.
Cuota de CPU. La relación entre el tiempo de CPU del programa y su tiempo de espera en la cola de preparados.
CuotaCPU = tCPU / (tCPU + tpreparado)
Equidad o predecibilidad. Los criterios anteriores se miden aplicando parámetros estadísticos entre los procesos del sistema. La media parece ser el parámetro más indicativo, pero otros parámetros de la distribución estadística, en particular la varianza, son de gran interés. Una varianza pequeña indica un comportamiento homogéneo, lo que es deseable por dos motivos: por una parte el comportamiento de los programas es más predecible; por otra parte indica un comportamiento más ecuánime y menos discriminatorio. En cambio, varianzas muy grandes pueden indicar riesgo de inanición, para algunos programas.
Además, hay que considerar otros criterios que afectan al rendimiento del sistema:
- Productividad (throughput). Número de programas que se ejecutan por unidad de tiempo.
- Eficiencia. Porcentaje de tiempo que la CPU se mantiene ocupada haciendo trabajo útil. Por trabajo útil se entiende la ejecución de código de los programas (y de los servicios solicitados por éstos). El tiempo que la CPU permanece ociosa y el tiempo que la CPU invierte en las tareas propias de la gestión de procesos (scheduler y dispatcher), se computan como tiempo perdido.
Nota
Como habrás observado, estos criterios no son exclusivos del ámbito de los sistemas operativos. Por ejemplo, la latencia, entre otros muchos ámbitos, se utiliza para medir la calidad del servicio de acceso a Internet, al igual que el throughput (velocidad de acceso). Puedes también utilizar la eficiencia para medir el aprovechamiento que haces de tu tiempo de trabajo, o, en el plano espacial, para calcular por ejemplo la ocupación de las viviendas de una ciudad. Parámetros de equidad se usan en el ámbito social, por ejemplo para medir la distribución de la renta de un país.
Políticas de planificación¶
Una política es una estrategia o un plan destinado a conseguir un objetivo. Una política, en nuestro caso de planificación, puede implementarse mediante diferentes mecanismos. Aquí no nos vamos a ocupar de los mecanismos concretos, así que el grafo de procesos que ya conocemos servirá como marco conceptual para hablar de políticas de planificación:
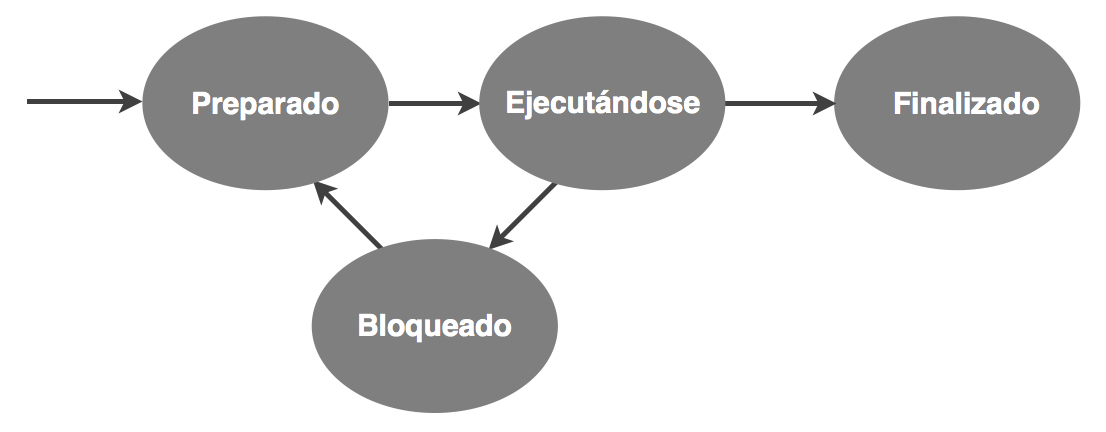
Abordaremos primero la cuestión de qué proceso elige el scheduler para ocupar la CPU, suponiendo que el sistema aplica la planificación únicamente cuando la CPU queda libre, bien porque un proceso finaliza, bien porque se bloquea.
La política más sencilla es la de primero en llegar, primero en ser servido, FCFS, que se implementa gestionando la cola de preparados con disciplina FIFO. Como esta política no está pensada teniendo específicamente en cuenta ninguno de los criterios que hemos definido, no deberíamos esperar de ella, en principio, grandes cosas, como puedes comprobar. Si un programa que necesita mucho tiempo de CPU está por delante de varios programas ligeros, los tiempos medios de respuesta y finalización se resienten. A esto se le llama efecto convoy, y es exactamente lo que ocurre cuando nos encontramos en la cola del supermercado con un paquete de galletas detrás de una familia que ha hecho la compra mensual, o cuando subiendo un puerto con nuestro deportivo alcanzamos un camión.
Por supuesto, esperamos que el camión se eche a un lado, y que la familia de la compra mensual nos deje pasar antes. ¿Por qué? Ambos pierden muy poco en cuanto a su tiempo de finalización, mientras nosotros ganamos mucho. Podemos imaginar por tanto una segunda política, el más corto primero, SJF (Shortest Job First), en la que los procesos se eligen por orden inverso a su tiempo de ejecución. De hecho, SJF es óptima en cuanto a tiempos medios de respuesta y finalización.
El problema de la política de planificación SJF es que, al contrario de lo que ocurre con la velocidad de los vehículos y con los carritos de la compra, estimar el tiempo de CPU que va a gastar un proceso no es evidente. Es decir, en general no existe un mecanismo que implemente fielmente SJF. Es necesario basarse en proyecciones a partir del comportamiento del proceso durante sus anteriores estancias en la CPU. Aunque esto no es muy fiable, es lo único que pueden hacer los sistemas operativos de propósito general como Linux.
Prioridades¶
La proyección tiempo necesario de CPU de un proceso en base a su historial puede usarse para definir una prioridad para el proceso; mayor prioridad cuanto menor consumo previsto. Además esa prioridad puede recoger otras características del proceso. El scheduler tomaría entonces el valor de la prioridad como único parámetro para decidir qué proceso elegir. Por lo tanto, las prioridades constituyen un mecanismo muy general para la planificación.
Veíamos que en Linux se establece una prioridad inicial para los procesos. En algunos casos, la prioridad inicial no cambia durante la ejecución del proceso. Se habla entonces de prioridades estáticas. En Linux esto sucede para los procesos del sistema (los que atienden los servicios del sistema) y para los procesos de tiempo real, que tienen asignadas las prioridades más altas. El resto de procesos, los procesos de usuario, utilizan prioridades dinámicas. La prioridad de un proceso de usuario se recalcula cada vez que pasa a preparado, premiándolo o castigándolo en función de su cuota de CPU desde el recálculo anterior, siempre dentro del rango de prioridades de usuario.
Nota
Solo a modo ilustrativo: las prioridades de las versiones actuales de Linux están entre 0 y 140, correspondiendo valores más bajos a prioridades más altas. Las prioridades estáticas ocupan el rango 0-99, mientras que las dinámicas se mueven en el rango 100-140.
Todos los sistemas operativos de propósito general utilizan políticas de prioridades análogas a esta, aunque los mecanismos de implementación puedan diferir.
Expulsión¶
¿Qué pasaría si un programa ejecuta un bucle infinito? Las políticas que hemos visto no pueden impedir que el proceso se adueñe de la CPU para siempre. Por esta razón, los sistemas operativos contemplan la expulsión del proceso que ocupa la CPU. Esto nos lleva a introducir una nueva transición en el grafo:
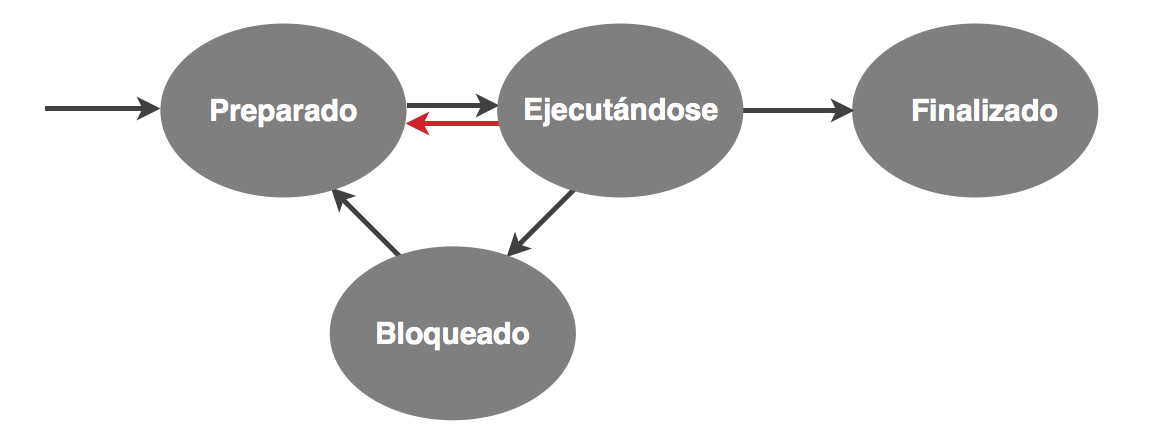
Hay dos formas básicas de expulsar a un proceso, que no son excluyentes.
- Expulsión por evento. Cuando se produce la transición de un proceso a preparados (ya sea cuando se crea el proceso o cuando se cumple la condición de desbloqueo), se da la oportunidad a dicho proceso (y al resto de procesos preparados) de entrar a la CPU. Esta forma de expulsión resulta necesaria si el sistema pretende soportar procesos de tiempo real, como es el caso de Linux, además, claro está, de asignar las prioridades estáticas más altas a los procesos de tiempo real.
- Expulsión por tiempo. Cuando el proceso que está ejecutándose ha rebasado cierto límite de tiempo, llamado quantum, se le expulsa. Esto puede ser muy beneficioso para los tiempos de respuesta y para una distribución equitativa de estos, como vamos a ver.
Los sistemas operativos de propósito general, y por supuesto Linux, incluyen ambas formas de planificación.
Sistemas de tiempo compartido¶
Linux es un sistema de tiempo compartido, lo que significa que el tiempo de CPU se comparte de manera más o menos equitativa entre los procesos del sistema. Para proporcionar tiempo compartido es imprescindible una política de expulsión por tiempo. Además, si se utilizan prioridades estas no pueden ser estáticas, ya que esto puede llevar a la inanición de los procesos de prioridades bajas. Hemos dicho que Linux asigna prioridades estáticas para algunos procesos, como los del tiempo real. Por supuesto, un sistema Linux que se dedique a tareas de tiempo real de forma intensiva, difícilmente podría proporcionar tiempo compartido a los procesos de usuario, porque los tiempos de respuesta de estos se resentirían notablemente. Queda claro que la convivencia entre ambos tipos de procesos es problemática, por lo que en un sistema de propósito general como Linux se entiende que los procesos de tiempo real son excepcionales (los procesos del sistema están acotados en cuanto a número y necesidades de CPU).
Un sistema de tiempo compartido alcanza su mayor expresión cuando combina la expulsión por tiempo con una política FCFS. A esta política de planificación se la denomina de turno circular o, más frecuentemente, round-robin. Obsérvese que la expulsión por tiempo elimina el efecto convoy. Además, con FCFS, dado un número de procesos N en el sistema, para un quantum q se obtiene que el tiempo de respuesta de cualquier proceso está acotado por (N–1)q. La política round-robin es una gran noticia tanto para el tiempo de respuesta como para el criterio de equidad.
A partir de aquí podemos plantearnos la siguiente reflexión. Marquémonos el objetivo de conseguir que el usuario propietario de un proceso perciba para su proceso un tiempo de respuesta, tr, virtualmente nulo; es decir, que el sistema se comporte siempre de manera aparentemente instantánea. Podemos controlar el tiempo de respuesta modificando N y/o q. Conociendo o acotando N, podemos calcular q para la cota de tr elegida como objetivo. Esto es muy interesante, porque nos hace percibir al sistema, desde el punto de vista de nuestro proceso, como que le proporciona un procesador virtual dedicado con una velocidad 1/N de la del procesador real, ya que 1/N es precisamente la quota de CPU que tiene garantizado el proceso. Este comportamiento se denomina procesador compartido.
Ahora bien, ¿son capaces los sistemas de tiempo compartido de hoy en día de proporcionar el concepto de procesador compartido? Vamos a hacer unas cuentas.
Probablemente ningún usuario sea capaz de percibir retardos de 0,1 segundos, luego esta podría ser la cota objetivo para tr. Imaginemos que tenemos 100 procesos ejecutables. En este caso, un quantum de 1 ms sería suficiente para proporcionar procesador compartido. Pero, y ¿si tenemos 1000 procesos? Bajemos entonces el quantum a 0,1 ms. ¿Y porqué vamos a quedarnos ahí? Si seguimos reduciendo el quantum, podemos admitir más procesos o mejorar aún más el tiempo de respuesta. O ambas cosas.
¿Dónde está el límite? Como ya habrás adivinado, una expulsión no sale gratis, ya que conlleva un cambio de contexto. Si q no está significativamente por encima del tiempo de cambio de contexto, el tiempo que el procesador dedica a ejecutar cambios de contexto (recuerda que es tiempo perdido) puede llegar a ser una fracción importante del tiempo dedicado a ejecutar el código de los procesos (tiempo de trabajo útil), lo que penaliza la eficiencia.
En sistemas como Linux el quantum es del orden de 100 ms. Hay que tener en cuenta que la proporción de procesos ejecutables en el sistema suele ser muy pequeña, y la mayoría de los procesos no agotan el quantum. Además Linux reduce el quantum de los procesos que lo rebasan.
