
Gestión de procesos¶
Ya conocemos el concepto de proceso UNIX como entidad que representa un flujo de ejecución con un contexto asociado. Los procesos son las entidades clave de los sistemas operativos multiprogramados como UNIX/Linux y son la base para un tipo de programación concurrente.
Un proceso consume recursos, fundamentalmente tiempo de CPU, además de memoria para almacenar el contexto y de otros recursos relacionados con la entrada/salida. Típicamente, un proceso requiere la CPU durante un periodo de tiempo, realiza alguna operación de entrada/salida, y vuelve a requerir la CPU, repitiéndose este ciclo hasta la finalización del programa. Durante su ejecución, el proceso pasa por diversos estados, que representábamos para un ejemplo particular sobre Linux mediante un grafo de transiciones de estado:
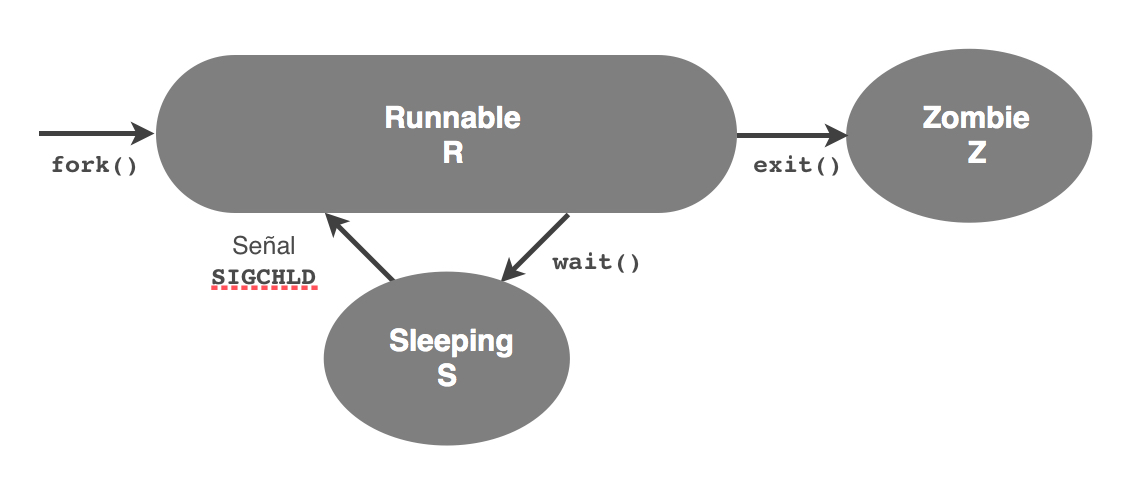
Este modelo deja de lado muchos detalles que Linux tiene que considerar a la hora de gestionar el gran número de procesos que conviven en el sistema. De entrada, el estado R que representa al proceso en disposición de ejecutarse, abstrae el hecho de si el proceso realmente está ejecutándose. Esto depende fundamentalmente de si hay un recurso de ejecución disponible para el proceso, pero esto no tiene por qué ser siempre así. Para actuar en consecuencia, el sistema tiene que ser capaz de distinguir esta circunstancia cuando se crea o se despierta un proceso.
El modelo de procesos de UNIX era tan válido hace décadas, cuando los computadores tenían un único procesador capaz de ejecutar una secuencia de instrucciones, como ahora, con servidores con varios procesadores, cada uno con muchos cores, que a su vez son capaces de ejecutar más de una secuencia (thread) de instrucciones. En definitiva, la abstracción proceso es lo suficientemente potente como para ocultar al programador todos los detalles de cómo se implementa la concurrencia, de forma que este se centre únicamente en la lógica del programa, y no en la máquina que lo ejecuta.
Ya que este es un curso de programación concurrente, no entraremos en la riqueza de detalles de la arquitectura, muy compleja en todo tipo de máquinas actuales, desde un servidor multiprocesador a una Raspberry Pi. Sin embargo, sí deberíamos interesarnos en algunas cuestiones de la gestión de procesos que tienen impacto en el rendimiento de nuestros programas.
Por generalizar, llamaremos CPU al recurso de procesamiento, ya sea un procesador o un core. Esta simplificación nos mantendrá a salvo de los detalles farragosos al tiempo que nos permitirá comprender la mayor parte de las implicaciones sobre el rendimiento. El número absoluto de CPUs no es relevante salvo que nos dediquemos a la computación de altas prestaciones. Más interesante para la mayoría de las aplicaciones resulta el tiempo que los procesos disfrutan de CPU frente al que están esperando, de la misma forma que cuando salimos de un supermercado no nos fijamos tanto en el número de cajas como en la longitud de las colas. Como punto de partida para este propósito, resulta conveniente definir un diagrama de transición de estados que distinga la espera por CPU del uso de la CPU por el proceso. De esta forma, podemos representar el siguiente grafo de transición de estados general:
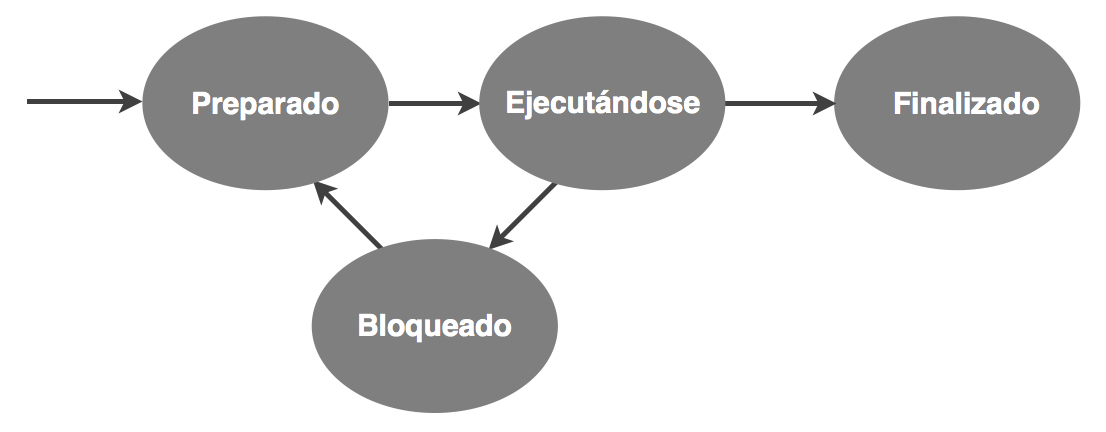
Donde hemos prescindido de la jerga de UNIX para denotar los estados. Aquí podemos apreciar el desdoble del estado R de UNIX en los estados Preparado, que representa a un proceso que podría ejecutarse si dispusiera del recurso CPU, y Ejecutándose, que representa al proceso que realmente está haciendo uso de la CPU.
Representación de los procesos¶
A partir del grafo resulta sencillo imaginar el conjunto de procesos en el sistema operativo como un sistema de colas con procesos esperando por recursos. El estado Preparado representaría una cola de procesos esperando CPU. Recuerda que el estado Bloqueado es múltiple, por lo que se representaría mediante un conjunto de colas, una por estado de bloqueo (por ejemplo, entrada de teclado, señales…). En general, si consideramos que un proceso se bloquea para usar un dispositivo de entrada/salida (aunque no siempre es así), podríamos ilustrar el funcionamiento del sistema operativo de la siguiente forma:
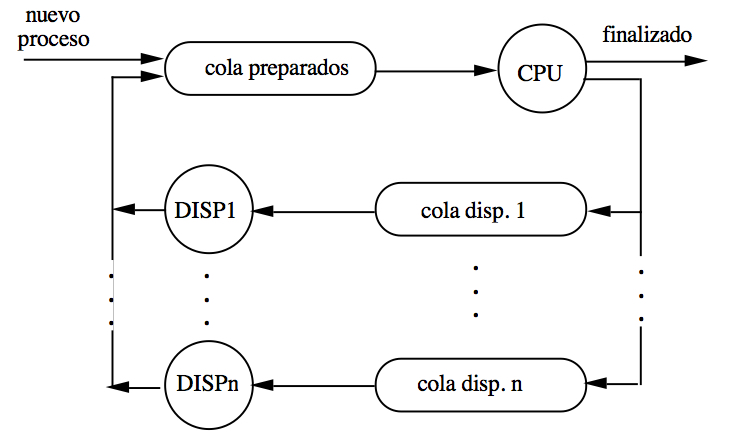
Esto nos permite hacernos una idea bastante intuitiva de cómo se gestionan los procesos en un sistema operativo. Faltan muchos detalles, como definir la disciplina en las colas (la de la caja del supermercado es FIFO, pero no tiene por qué ser el caso aquí, como veremos), o cómo se representa un proceso. Nos ocuparemos ahora de esto último.
Nota
Cuando hay varias CPUs, se puede plantear si el sistema debería tener una cola de preparados única o una por cada CPU. En principio, una única cola es más flexible, aunque dependiendo de la arquitectura podría interesar la segunda alternativa para potenciar la afinidad del proceso con la CPU, es decir, el hecho de que parte de su contexto permanezca en la memoria cache de esa CPU desde una anterior visita a la CPU (lo que se denomina huella del proceso). El tema es complejo y a menudo se utilizan soluciones mixtas. En cualquier caso, queda fuera de los objetivos de este curso.
Un proceso es una abstracción, pero necesita ser representado físicamente de alguna forma. Ya sabemos que un proceso se identifica por su identificador de proceso (PID) y se caracteriza por un conjunto de información que es lo que denominamos contexto. El contexto de un proceso puede ser bastante voluminoso (recuerda que incluye por ejemplo el código del programa), de forma que hay que representarlo de alguna forma compacta, por ejemplo, mediante apuntadores (en el caso del código, a las páginas de memoria donde está cargado). De esta forma, los sistemas operativos almacenan el contexto, directamente o mediante apuntadores, en una estructura que se suele denominar Bloque de Control del Proceso o PCB (Process Control Block), y que constituye la representación del proceso. El PCB de un proceso Linux incluye:
- El identificador del proceso.
- El identificador del proceso padre.
- El usuario y grupo propietarios del proceso.
- El estado del proceso.
- El apuntador a la pila del proceso (incluye el contador de programa, PC).
- Los apuntadores a las tablas de páginas del proceso.
- La tabla de descriptores de ficheros.
- El estado de las señales.
- Tiempos de CPU, recursos consumidos, etc.
- La prioridad del proceso.
- Un apuntador al siguiente PCB.
Cuando se crea un proceso, Linux reserva una de estas estructuras para él y la apunta desde una tabla de procesos. El identificador del proceso es el índice de esa tabla. Además, al asignarle un estado (inicialmente Preparado, R), lo inserta en la cola que representa el estado:
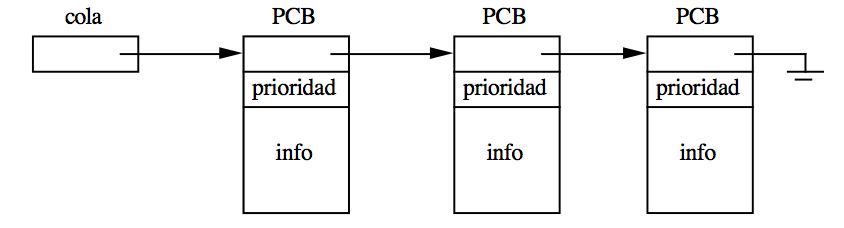
El sistema operativo mantiene la representación del modelo de colas moviendo PCBs de una cola a otra cuando se produce una transición de estado. Por ejemplo, cuando un proceso se bloquea mueve el PCB de ese proceso a la correspondiente cola de bloqueado y mete en la cola de la CPU (que puede verse como una cola de un único elemento), un PCB de la cola de preparados. Como veremos más adelante, Linux utiliza prioridades para mantener ordenada la cola y elegir al primer proceso. ¿Qué pasa si la cola de preparados está vacía? El sistema usa el artificio del proceso nulo, que siempre existe y está preparado para ejecución en la última posición.
Debes tener en cuenta que hasta ahora nos estamos refiriendo a la representación de los procesos. El modelo de colas de PCBs resulta útil al sistema para organizar la gestión de los procesos y ofrecernos información sobre ellos. Pero las transiciones de estado tienen implicaciones más profundas. Poner a ejecutar un proceso en la CPU significa cargar su contexto en los registros del procesador tras haber guardado adecuadamente el contexto del proceso que abandona la CPU. A esta operación se la denomina cambio de contexto.
Cambio de contexto¶
El cambio de contexto (context switch) es la acción de cargar el procesador (PC, puntero a pila, registros…) con el contexto del proceso que pasa a ocupar la CPU (es decir, pasa a estado ejecutándose), salvando previamente el contexto del proceso que abandona la CPU en su PCB. Un cambio de contexto se realiza en el ámbito de una llamada al sistema o interrupción, en modo protegido, e implica la siguiente secuencia de acciones a ejecutar por el sistema operativo (se suele llamar dispatcher a la función encargada de ello):
- Guardar el estado del procesador en el PCB del proceso que abandona la CPU.
- Eliminar el PCB del proceso saliente de ejecución. La cola destino del PCB depende de la causa que provocó el cambio de contexto.
- Elegir un nuevo proceso para entrar a ejecución. Esta función la realiza el scheduler, como veremos más adelante.
- Mover el PCB del proceso seleccionado a la cola de ejecución.
- Restaurar el contexto del proceso seleccionado desde su PCB y transferirle el control.
Las operaciones de guardar y restaurar el estado del procesador implican el manejo del puntero a la pila (registro stack pointer). Un sistema operativo como Linux está programado casi enteramente en C, pero esta operación es muy dependiente del procesador y se implementa directamente en lenguaje máquina.
Esta animación sobre el cambio de contexto ilustra una forma simple de cómo se puede implementar, aunque existen otras alternativas, dependiendo del soporte hardware. Como podrás observar, en este caso se hace un hueco en la pila del proceso interrumpido debajo del bloque de activación de la rutina de atención o trap que ejecuta, para almacenar allí el estado del procesador. Aunque este tema se escapa de los objetivos del curso, puedes encontrar más información sobre el cambio de contexto en el libro de Stallings, por ejemplo, así como en cualquier tratado sobre la implementación del kernel de Linux.
El cambio de contexto es una operación relativamente costosa en tiempo, no tanto por las acciones directamente involucradas como por sus consecuencias indirectas: el nuevo proceso se va a encontrar con que el proceso saliente ha dejado una huella sobre las memorias cache que al proceso entrante no le sirve para nada, por lo que sus accesos a memoria (a su contexto) serán más lentos hasta que el proceso tenga una buena parte del contexto cargado en las caches.
