
Parte 4. Una solución multi-hilo para nuestro robot Linux¶
El equipo de bioquímicos ha desarrollado la siguiente fórmula para el cálculo de las probabilidades de vida:
P(X,Y) = (C(X,Y)/5)·(H(X,Y)/5)
Donde P(X,Y) es la probabilidad de vida entre X e Y, C(X,Y) el valor medio de las medidas de CO2 entre X e Y, y H(X,Y) el valor medio de las medidas de humedad entre X e Y.
De esta forma, como resultado de procesar la secuencia ejemplo:
A 0 d e 0 0 B 3 c 5 C …
deberemos interpretar que P(A,B) = 0 y P(B,C) = 0.32, y en consecuencia el módulo MCPV deberá escribir por la salida estándar:
A-B: 0.00
B-C: 0.32
…
Por otra parte, en la última reunión presentamos los resultados de nuestros experimentos sobre el procesado concurrente de los simuladores para generar la secuencia entrelazada de datos. Los coordinadores del proyecto nos felicitaron por el trabajo, nos solicitaron detalles sobre el manejo de procesos en Linux y mostraron su preocupación sobre el consumo de recursos (memoria y energía). Alguien sugirió la alternativa de generar la concurrencia mediante threads (hilos) utilizando, por compatibilidad, la biblioteca estándar pthreads de POSIX. Nos comprometimos a estudiarlo.
Finalmente, se difundió un documento final de especificación del robot explorador.
Actividad 4.1 Una maqueta del robot utilizando el shell¶
Dedicación estimada: 2 horas y media¶
De momento aparcaremos la exploración del uso de threads y continuaremos con el modelo de procesos como prueba de concepto para la integración de todas las partes del MCPV utilizando el shell de Linux. Lo primero que hay que resolver es la comunicación entre los componentes, para lo que desarrollaremos una maqueta que nos ilustrará la arquitectura de nuestra solución:
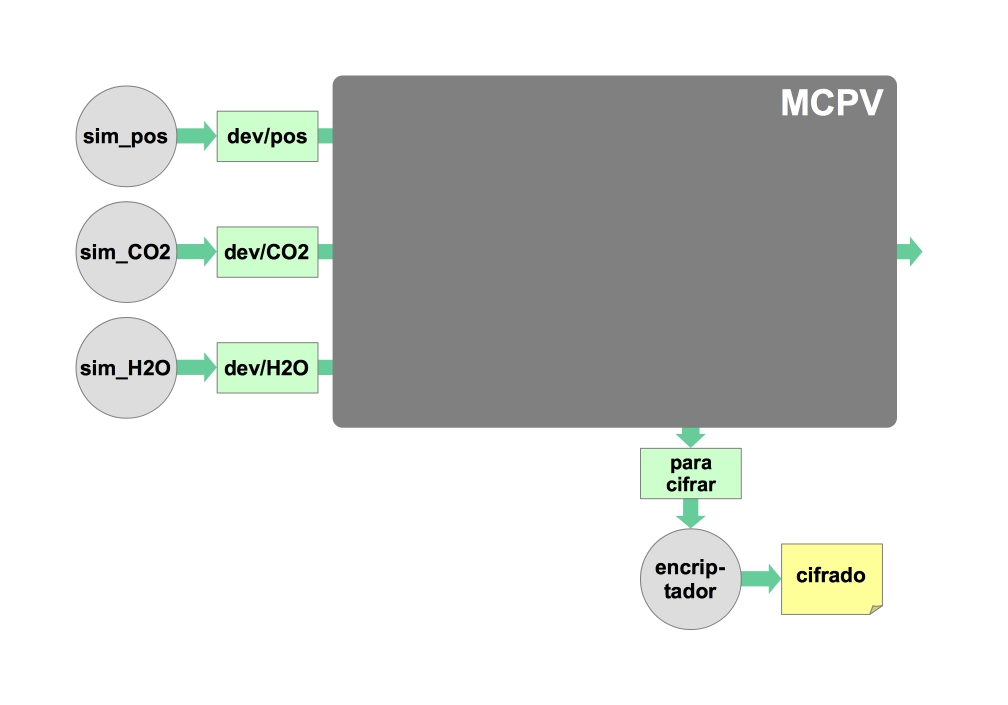
Algunos de los elementos de la maqueta ya los tenemos. Otros, los ocultados tras la caja gris de la figura, que corresponde al módulo MCPV propiamente dicho, están aún pendientes.
Qué hay que hacer¶
Esta batería de órdenes del shell te servirá para explorar sus posibilidades en cuanto a la comunicación entre procesos. Consultando el
mansi es necesario, intenta anticipar el resultado de la ejecución de cada orden de la secuencia.Has comprobado cómo dos filtros pueden comunicarse a través de la entrada/salida estándar utilizando el operador de comunicación
|, al que llamaremos pipe (tubería). Más adelante nos centraremos en cómo el shell consigue esta forma de comunicación entre programas. De momento, aprovecharemos los pipes del shell para montar una versión de nuestro módulo. Para empezar con algo muy sencilo, utiliza los pipes del shell para conectar la salida del simulador de CO2 con la versión del MCPV que desarrollaste en la Parte 2.En la Parte 3 hemos aprendido cómo generar concurrencia de procesos, y ahora ya sabemos como comunicar dos procesos, un productor de información con un consumidor de información. Pero nuestro MCPV definitivo no estará alimentado por uno sino por tres simuladores. ¿Cómo conectamos tres productores con un consumidor? ¿Podemos utilizar un fichero como sumidero de los tres consumidores, de forma que nos proporcione la secuencia entrelazada? Unas pruebas te permitirán responder a esta pregunta. Lanza los simuladores concurrentemente redirigiendo sus salidas a un fichero. ¿Contiene el fichero la secuencia entrelazada?
Los ficheros ordinarios están pensados para entrada/salida secuencial. Como vimos, cada proceso dispone de un descriptor del fichero que le proporciona un acceso privado al fichero, es decir, no comparte la posición en la que ha leído/escrito. ¿Proporciona Linux algún elemento de la abstracción fichero que permita compartir el acceso? La respuesta es afirmativa: se denominan colas fifo. Los pipes que usa el shell son, como veremos, un tipo particular de colas fifo. Explora en el
mancómo se crea una cola fifo mediante la ordenmkfifo(1). Ahora ya sabes cómo mezclar en una secuencia entrelazada las salidas concurrentes de los tres simuladores.Ya estamos en disposición de completar la maqueta. Vamos a incorporar al esquema los dispositivos tal como se definirán en el sistema a instalar en el robot:
/dev/pos,/dev/CO2y/dev/H2O. La única diferencia será que los representaremos en nuestro directorio de trabajo para no tener que manejar permisos de root (es decir,./dev/pos, etc). Una cuestión a resolver es con qué tipo de elemento Linux implementamos los dispositivos, pero si has entendido el punto anterior de la actividad la respuesta debe estar clara. Necesitarás también un consumidor de la secuencia entrelazada que genere las probabilidades de vida. Puedes usar este filtro. Este es el esquema resultante: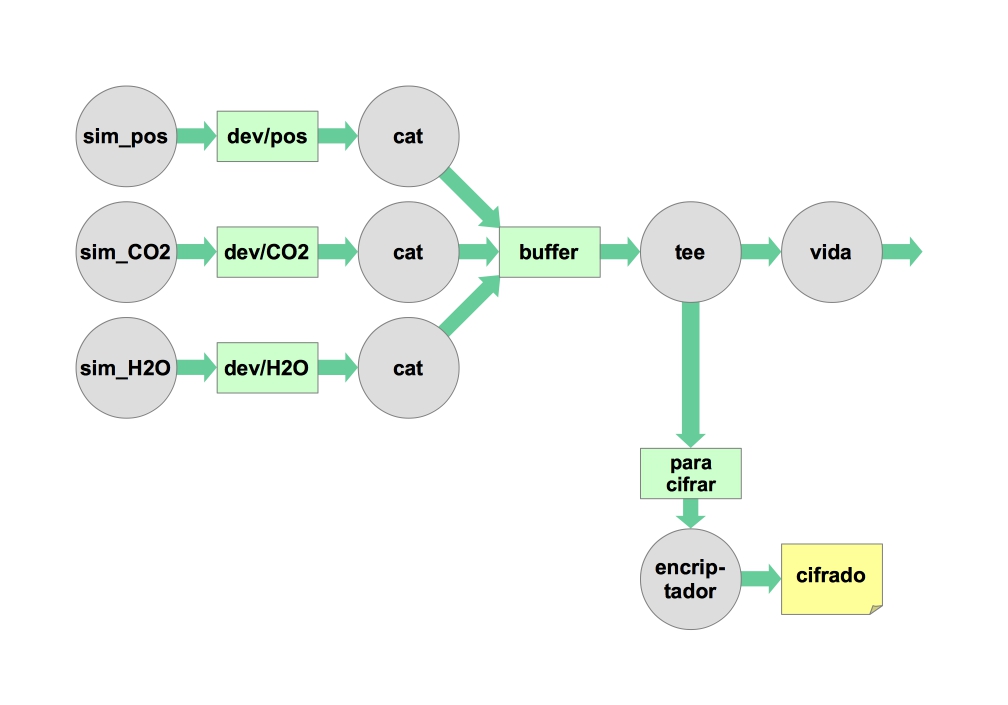
Elabora un shell script de nombre
Maquetaque implemente este esquema y pruébalo.
Resultados¶
La actividad se evalúa como correcta si el script funciona de acuerdo al esquema de la maqueta.

Actividad 4.2. Fontanería de procesos en Linux¶
Dedicación estimada: 2 horas¶
En la actividad anterior hemos conocido los mecanismos del shell para comunicar programas. Primero, el operador | nos ha permitido conectar la salida estándar de un programa productor con la entrada estándar de otro programa consumidor. Esta forma de comunicación nos proporciona un mecanismo muy potente para componer aplicaciones, llevando un paso más allá el concepto de redirección. La metáfora de una tubería por la que la información fluye de uno a otro programa es realmente ilustrativa de su funcionamiento. Por definición, este flujo de información sigue un orden fifo, por lo que un pipe es básicamente una cola fifo.
La segunda forma de comunicación usa las colas fifo creadas con mkfifo. Estos elementos reciben un nombre en el momento de su creación para luego ser usados de forma análoga a los ficheros. Así, estos pipes con nombre pueden ser usados por cualquier programa con los derechos de acceso adecuados. Como consecuencia, una de estas colas fifo puede ser usada concurrentemente por n productores y m consumidores. Esto nos ha permitido usarlo para montar un esquema de comunicación 3:1, con un programa consumiendo la secuencia entrelazada de datos de los tres sensores.
Hemos comprobado que un programa puede utilizar una cola fifo como cualquier fichero. Podemos deducir por lo tanto que utiliza las mismas llamadas al sistema de entrada/salida que ya conocemos. En esta actividad vamos a explorar el uso de las colas fifo por las llamadas al sistema de Linux.
Qué hay que hacer¶
- Analiza este código, compílalo y ejecútalo. Te resultará familiar su comportamiento. De nuevo, en este ejemplo se pone de manifiesto la independencia entre la interfaz de programación de la entrada/salida y los dispositivos, gracias a la abstracción fichero. No debe sorprenderte la única llamada al sistema nueva que contiene, que puedes explorar en el
man. De hecho, sería innecesaria si la cola fifomififohubiera sido creada previamente, por ejemplo con la ordenmkfifo. - El código que has visto redirecciona las salidas estándar de los simuladores y la entrada estándar de
vida. Esto es exactamente lo que el shell hace con los operadores<y>. Dibuja la tabla de descriptores del proceso y, ejecutando mentalmente las llamadas al sistema, refleja cómo quedan los descriptores estándar de los procesos hijos (no olvides que estos reciben mediantefork()una copia privada del padre). Verifica que el comportamiento del programa es coherente con el estado de las tablas de descriptores que has elaborado sobre el papel. - Pero, ¿cómo interpreta el shell el operador
|? Es decir, ¿cómo comunica dos procesos mediante un pipe que no se ha creado explícitamente? Este otro código muestra cómo conectar dos programas (./sim_CO2ycat) de la misma forma que lo hace el shell. Cambia el programacatpor la versión deMCPVque desarrollaste en la Parte 2 y obtendrás el mismo comportamiento que observaste entonces. Debes fijarte en varios aspectos del código. Primero, las nuevas llamadas al sistema. Explóralas en elman. La combinación de estas llamadas permite crear un pipe sin nombre para que los procesos lo usen correctamente con ayuda de la llamadaclose(), que prepara la tabla de descriptores adecuadamente. Analiza el código con atención, porque el artificio es más elaborado que el de los pipes con nombre del ejemplo anterior. Como hiciste entonces, representa los cambios que van sufriendo las tabla de descriptores y verifica que el comportamiento del programa es coherente con el estado en que quedan.
Resultados¶
La actividad se evalúa como correcta si la representación que has obtenido para las tablas de descriptores de ficheros en los dos ejemplos es consistente con el respectivo comportamiento de cada programa.
Actividad 4.3. Construyendo una aplicación multi-hilo¶
Dedicación estimada: 2 horas¶
Las maquetas anteriores nos han mostrado lo sencillo que es comunicar procesos productores y consumidores mediante colas fifo, bien para parejas de procesos, bien para n productores y m consumidores. Este es el tipo de esquema que requiere nuestro MCPV. En la actividad previa has aprendido a implementarlo prescindiendo del shell, pero, como nos han sugerido, debemos diseñar la aplicación de manera más eficiente, utilizando threads (hilos) en vez de procesos. Para garantizar cierta compatibilidad nos sugieren el uso de la biblioteca estándar POSIX de hilos (pthreads).
Lo que hace más eficientes a los hilos es que los hilos de un proceso comparten memoria y por lo tanto pueden comunicarse entre ellos mediante variables del programa. Esto nos permite prescindir de las colas fifo de Linux. En su lugar, tendremos que implementar nuestra propia cola fifo en memoria para conseguir la secuencia entrelazada de datos. Este es el esquema de la aplicación que vamos a construir.
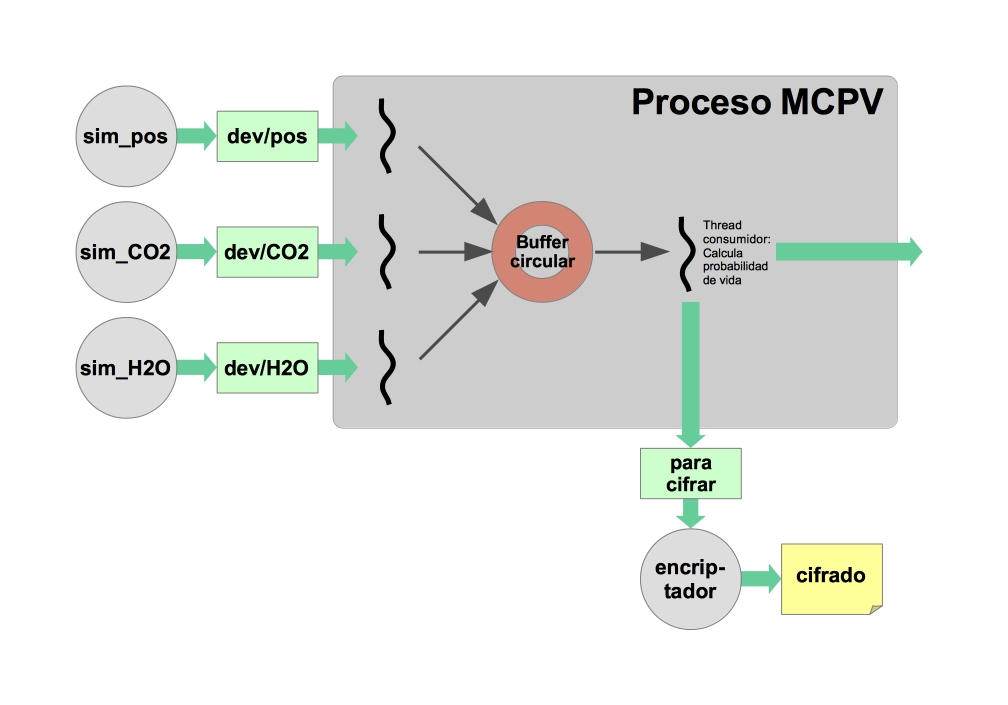
Como otras veces, iremos paso a paso. En esta actividad vamos a limitarnos a construir una prueba con un único productor y un consumidor para familiarizarnos con los hilos y su forma de comunicación.
Qué hay que hacer¶
Para comunicar los hilos necesitamos la cola fifo implementada como un buffer en memoria. Idealmente, esta debería tener longitud infinita, para que los productores siempre encontraran espacio para dejar la información. Como esto no puede ser así, se suele recurrir a implementarlo como un buffer circular. Esta biblioteca proporciona el código de las funciones de acceso al buffer. Puedes compilarla separadamente junto al fichero buffer_circular.h. Si no te es familiar la implementación de un buffer circular, analiza el código de la biblioteca.
Ahora necesitamos crear un par de hilos y comunicarlos mediante las primitivas del buffer circular. En la página
pthreads(7)delmanencontrarás información sobre el uso de las funciones de la biblioteca pthreads. Inspirándote en los ejemplos que encontrarás en la Web (como este código propuesto por Mirela Damian, de la Universidad de Villanova), no te será difícil construir un programa con un hilo productor que lea datos de un sensor y un hilo consumidor que simplemente los copie en la salida estándar, utilizando el buffer circular para comunicar ambos hilos. Limítate a usar solo las funciones de creación de hilos y de espera, tal como hace el ejemplo de la Universidad de Villanova. Como en la maqueta, utiliza el simulador para redirigir los datos al sensor. Ajustando con retardos el ritmo con el que el consumidor lee los datos del buffer, puedes forzar situaciones de buffer lleno y buffer vacío (utiliza un buffer de pequeño tamaño para facilitar las pruebas).Nota
Quizás tengas que montar explícitamente la biblioteca pthreads para compilar:
gcc miprograma.c -o miprograma -lpthread.
Resultados¶
La actividad se evalúa como correcta si has conseguido construir el programa multi-hilo de prueba propuesto y este maneja las funciones de la biblioteca del buffer circular de forma que los resultados sean coherentes.
Actividad 4.4. ¿Procesos o hilos?¶
Dedicación estimada: 45 minutos¶
Ya has visto que manejar hilos no es más complicado que manejar procesos, más bien al contrario. Entonces, ¿por qué sistemas como Linux ofrecen ambos mecanismos para generar concurrencia? ¿Cuándo usar hilos y cuándo procesos? En esta actividad trataremos de aclarar algunas cuestiones al respecto.
Qué hay que hacer:¶
- Lee esta nota sobre procesos e hilos para hacerte una idea de las razones para usar procesos o hilos, en particular desde el punto de vista del rendimiento y la facilidad de programación.
Resultados¶
Evalúa lo que has aprendido con este test de autoevaluación. Repasa los conceptos en función de los resultados obtenidos.
Actividad 4.5. Los problemas de compartir información¶
Dedicación estimada: 3 horas¶
¿Puedes garantizar que el código de la actividad anterior funciona siempre correctamente?
Qué hay que hacer:¶
Prueba el ejemplo de la Universidad de Villanova. Se supone que al final de la ejecución cada uno de los dos hilos del ejemplo debería haber incrementado la variable
cnt1.000.000 de veces, luego su valor final debería ser 2.000.000. ¿Es así? ¿Te atreves a aventurar una explicación para el comportamiento observado?La programación multihilo (multithread) tiene muchas ventajas. Los hilos, al compartir variables en memoria, permiten a las aplicaciones intercambiar información de forma ágil y eficiente. Sin embargo, el acceso a ese elemento compartido (la variable
cnten el ejemplo) conduce a comportamientos inesperados. O no tan inesperados. Piensa que el ordenador en el que estás haciendo las pruebas tendrá varios cores donde los hilos concurrentes del programa se pueden ejecutar en paralelo. La situación es análoga a una que te será familiar: más de una persona trabajando sobre un documento compartido. El acceso al documento o a la variable compartida debe hacerse de forma coordinada para evitar las denominadas condiciones de carrera que conducen a los resultados que has observado en el ejemplo.Entonces, ¿desaparece del problema si mi ordenador tiene un único core? La respuesta es que no, aunque las condiciones de carrera serán menos frecuentes. Ten en cuenta que el scheduler del sistema operativo puede cambiar de un hilo a otro en cualquier momento. Es decir, las condiciones de carrera las produce la concurrencia, no el paralelismo. Por otra parte, puedes observar con una sencilla modificación del código que incrementar la variable en una única sentencia C (
cnt++), es decir, sin usar la variable local, no soluciona el problema. El compilador suele copiar la variable a un registro para incrementarla.El incremento de la variable
cntes lo que se denomina una sección crítica de código. La ejecución de una sección crítica debe coordinarse (o sincronizarse) de alguna forma para evitar las condiciones de carrera entre los procesos que acceden a la sección crítica. ¿Cómo coordinamos el acceso a la sección crítica? Te propongo como solución proteger la sección crítica con una variable compartidacerrojo(inicialmente a cero):while (cerrojo==1) ; /* Espera a que se abra el cerrojo */ cerrojo= 1; /* Echa el cerrojo */ ... /* Ejecuta la sección crítica (manejo de cnt) */ cerrojo= 0; /* Abre el cerrojo */
¿Es segura la utilización de este protocolo? En otras palabras, ¿garantiza que nunca va a haber más de un hilo ejecutando la sección crítica? Para demostrar que resulta seguro, deberías razonarlo cuidadosamente; si te parece que es inseguro, te bastará con describir un caso que pueda llevar a que varios hilos se encuentren modificando concurrentemente la variablecnt.
La idea del punto anterior, utilizar un cerrojo para regular el acceso a la sección crítica, no es mala. Como habrás adivinado, el problema está en la variable
cerrojo…que también es un recurso compartido. Es decir, para proteger el acceso a una sección crítica, ¡estamos creando otra sección crítica! El problema del acceso exclusivo a secciones críticas de código está muy estudiado y los conceptos y mecanismos muy asentados, como verás en los dos primeros puntos de esta presentación sobre la coordinación en el acceso a secciones críticas. También puedes consultar cualquier texto general sobre sistemas operativos o programación concurrente.Nota
Aunque en nuestro caso los problemas de coordinación son entre hilos, encontrarás que la literatura (y esta presentación) se refiere en general a coordinación entre procesos. El problema y las soluciones son las mismas. Si para los hilos una variable es un recurso compartido, para los procesos lo es un fichero. Por otra parte, en este contexto los términos coordinación y sincronización son sinónimos.
Ahora que conoces los mecanismos para proporcionar acceso exclusivo a las secciones críticas, deberías ser capaz de encontrar en la biblioteca pthreads las primitivas adecuadas para evitar las condiciones de carrera del contador. Busca el mecanismo más sencillo, el basado en cerrojos (locks) y modifica el código del contador de la Universidad de Villanova marcando las secciones críticas con estas primitivas. Comprueba que el código funciona ahora consistentemente.
¿Pueden producirse condiciones de carrera de este tipo en tu código de prueba del buffer circular? Seguramente no se van a manifestar tan fácilmente como las del contador, pero no tendrás problema en identificar secciones críticas en tu código si has entendido el concepto. Soluciónalo de la misma forma que hiciste con el contador y comprueba que funciona correctamente (¡al menos tan correctamente como antes!).
Nota
No modifiques del código de la biblioteca del buffer circular. Aplica la solución dentro de tu código de prueba.
Resultados¶
La actividad se evalúa como correcta si el (a) has solucionado el problema del contador, y (b) tras introducir las secciones críticas, el código de prueba del módulo del robot funciona correctamente.
Actividad 4.6. Mejorando la gestión del buffer compartido¶
Dedicación estimada: 4 horas¶
A continuación debemos resolver las situaciones de buffer lleno y buffer vacío, ya que las primitivas suministradas para la gestión del buffer no se adaptan del todo a la especificación. En la situación de buffer vacío, en lugar de devolver un carácter en blanco, vamos a dejar bloqueado al hilo consumidor hasta que haya algún elemento en el buffer. En cuanto a la situación de buffer lleno, para evitar que ocurra deberíamos definir un buffer lo suficientemente grande. Aun así, si el buffer se llenara vamos a priorizar la información de los sensores que ya está en el buffer con respecto a la entrada de nuevos datos, por lo que los productores, en vez de sobre-escribir la información más antigua del buffer (opción que usa la implementación original del buffer circular) se bloquearán hasta que haya espacio en el buffer.
Qué hay que hacer¶
Para implementar esta solución vamos a utilizar en el concepto de semáforo, que puedes encontrar descrito en la última parte de la presentación sobre coordinación. Si lo estimas necesario, consulta documentación adicional, que podrás encontrar en cualquiera de los textos sobre sistemas operativos de la bibliografía. Como verás, al igual que los cerrojos, los semáforos permiten coordinar el acceso a recursos (tanto entre hilos como entre procesos). Sin embargo los semáforos son un mecanismo más general que permite gestionar el uso de n unidades de un recurso. Esto es precisamente lo que pretendemos para el acceso al buffer: un buffer de longitud n puede verse como que posee n recursos huecos por los que los productores compiten. Análogamente, los consumidores compiten por los elementos ocupados del buffer. Teniendo esto en cuenta, podemos modelar una solución en la que, como comprobarás, productor y consumidor son duales. Cuando, con ayuda de la documentación suministrada, seas capaz de comprender el funcionamiento de este código, estarás en condiciones de pasar al punto siguiente.
El pseudo-código anterior del productor-consumidor con semáforos utiliza primitivas genéricas bajar() y subir() sobre semáforos. No te será difícil encontrar las funciones que la biblioteca de Linux ofrece para implementar estás primitivas sobre semáforos entre hilos. Consulta la página
man sem_overview. Te encontrarás con que hay más de una forma de utilizar semáforos, por lo que es conveniente que tengas en cuenta algunas cosas sobre el uso de semáforos en Linux.Modifica el código para que funcione de acuerdo al modelo productor consumidor con semáforos introducido en el punto anterior. Fíjate que debes preservar el acceso exclusivo a la sección crítica de código de acceso al buffer, tal como hacías antes, ya que lo que gestionan los semáforos es el uso de los recursos (huecos/items) del buffer, no el acceso exclusivo.
Prepara los casos de prueba para las situaciones de buffer lleno/vacío, y verifica su funcionamiento.
Nota
Define para las pruebas un tamaño pequeño para el buffer e introduce retardos para forzar las situaciones de buffer lleno/vacío. En cualquier caso, debes ser consciente de que es prácticamente imposible verificar empíricamente la corrección de un programa concurrente, dada la explosión combinatoria de situaciones posibles. Lo que realmente garantiza que tu programa es correcto es que has seguido escrupulosamente los esquemas de coordinación establecidos, que han sido verificados formalmente, y que usas las primitivas de la manera adecuada. En este sentido, es muy importante que chequees los códigos de error en cada llamada a las funciones de biblioteca.
Resultados¶
La actividad se evalúa como correcta si has utilizado las primitivas sugeridas y el código funciona de acuerdo a lo especificado.
Actividad 4.7. Terminando el proyecto¶
Dedicación estimada: 5 horas¶
Ya tenemos todos los elementos para abordar la implementación final de nuestro módulo para el robot explorador. Necesitamos añadir las entradas del resto de los sensores a cargo de nuevos hilos productores y el cálculo de las probabilidades de presencia de vida dentro del hilo productor, de forma que obtengamos finalmente una versión del módulo basada en hilos POSIX de acuerdo a la especificación.
Qué hay que hacer¶
Prepara los casos de prueba para la versión final. En la Actividad 4.1 construiste una maqueta, así que dispones de una buena base para desarrollar los casos de prueba, ya que la versión final deberá ser funcionalmente equivalente a la maqueta. Fíjate que los simuladores utilizan un generador aleatorio, así que para la verificación tendrás que prever una forma alternativa de suministrar al robot una entrada no aleatoria que permita controlar la verificación. Para ello puedes modificar ligeramente los simuladores para que lean los datos de una entrada preparada de acuerdo a los casos de prueba, o prescindir de los simuladores y alimentar los sensores a mano, utilizando diferentes terminales. En cuanto a las posibles condiciones de carrera sobre las variables compartidas (el buffer), ya que empíricamente no es posible garantizar su corrección, deberás verificar cuidadosamente que tu código sigue los esquemas establecidos para el acceso a las secciones críticas y para la gestión del esquema productor-consumidor; que las inicializaciones de las primitivas de sincronización son correctas, y que tratas las situaciones de error en el uso de las primitivas de coordinación.
Por una cuestión práctica, hay que introducir un mecanismo para finalizar la aplicación en el caso de que los sensores generaran los datos indefinidamente. Puedes usar el lanzador vigilante que desarrollaste en la Parte 3, pero te sugiero como alternativa que introduzcas un hilo reloj que termine en un tiempo determinado (tomado como parámetro). El hilo principal, una vez lanzados todos los hilos, simplemente debe esperar con
pthread_join()a que el reloj acabe. Este mecanismo puedes introducirlo ya mismo en el programa de prueba de la actividad anterior, ya que lo que queda por desarrollar es una extensión de lo que ya tienes.Vamos a proceder al desarrollo de la aplicación completa en dos fases. Ya tenemos un filtro
vida.cque calcula las probabilidades de vida, así que en una primera fase completaremos el esquema productor-consumidor de la forma indicada, pero el hilo consumidor se servirá del módulovidapara el cálculo de las probabilidades, de acuerdo al siguiente esquema: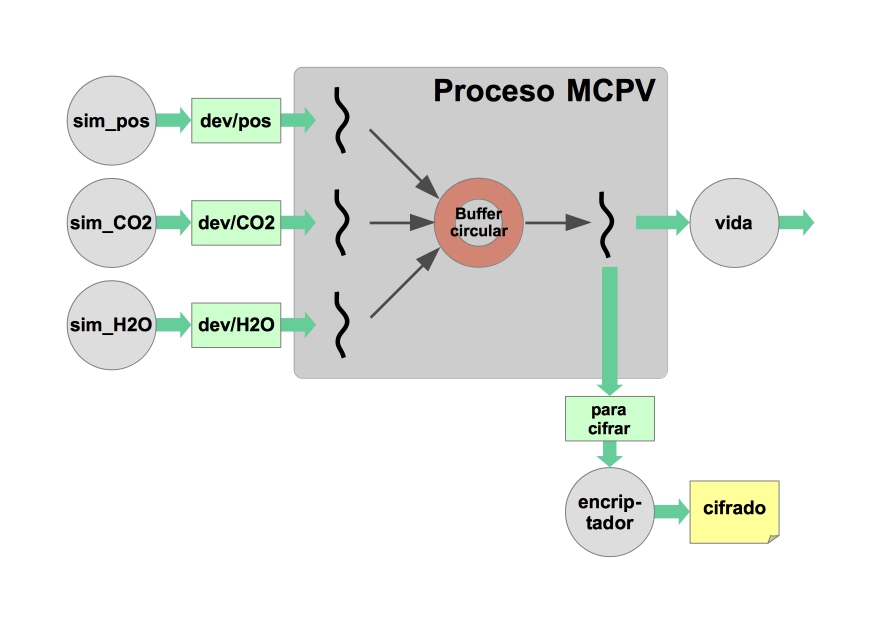
Programa de esta forma el módulo a partir del código que has ido desarrollando en las actividades anteriores. Luego, toma como base el script de la maqueta que construiste en la Actividad 4.1 y adáptalo para lanzar los procesos de esta nueva versión. Verifica su funcionamiento.
La versión anterior es funcionalmente equivalente a la definitiva, como ambas lo son a la maqueta. Si vamos a construir en esta segunda fase una versión del módulo estrictamente basada en hilos (salvo el encriptador) es únicamente por cuestiones de rendimiento.
Programa el módulo de acuerdo al esquema final, introduciendo el cálculo de las probabilidades de vida en el thread consumidor. Adapta el script de la primera fase para lanzar los procesos de esta versión y verifica su funcionamiento.
Nota
Esta segunda fase de construcción del módulo es quizás la parte más engorrosa del curso en cuanto a desarrollo de código. Sin embargo es la menos interesante desde el punto de vista de tu aprendizaje. Si no consigues hacerla funcionar en un tiempo razonable, siempre te quedará la versión modular del punto anterior. Habrás cumplido las especificaciones que te impone el consorcio del proyecto en una parte muy elevada y podrás justificar tu trabajo :-)
Resultados¶
La actividad se evalúa como correcta si el módulo funciona de acuerdo a la especificación.
Actividad 4.8. Los problemas de compartir no acaban aquí¶
Dedicación estimada: 2 horas¶
En vista del éxito del proyecto, la Unión Europea ha extendido la financiación para añadir más sensores y contratar más programadores. Los nuevos programadores se encargan de la programación de las funciones productoras de los datos obtenidos por los nuevos sensores. Aquí tienes el pseudo-código desarrollado por uno de nuestros programadores novatos, que incluye dos tipos de productor. Como supervisor/a del proyecto, debes verificar el código.
Qué hay que hacer¶
- Analiza el código desarrollado por el programador novato. Seguramente encontrarás algún problema. ¿Podrías aventurar sus consecuencias?
- Vamos a profundizar sobre el alcance del problema encontrado. Aunque cada sección crítica por separado está bien programada y los semáforos bien utilizados (el hilo ejecuta correctamente los protocolos de lock-unlock y subir-bajar), el código puede conducir a interbloqueos. Los interbloqueos son un problema inherente a la programación concurrente cuando se usa más de un recurso compartido. En nuestro caso tenemos la sección crítica de acceso al buffer (cerrojo mutex), y los huecos y elementos ocupados del buffer, regulados por sendos semáforos. Aunque el acceso a cada recurso por separado utilice las primitivas adecuadamente y estas estén correctamente implementadas, el código puede acabar con los procesos o hilos en una situación de bloqueo recíproco, sin que ninguno consiga finalizar. Puedes visualizar una situación de interbloqueo imaginando dos niños que pretenden dibujar. Los niños saben que para dibujar necesitan dos recursos: un lápiz y una hoja de papel. Si uno de los niños se apodera del lápiz y el otro del papel, ninguno acabará el dibujo. Deberían haber negociado antes un protocolo. Esta presentación sobre los interbloqueos formaliza el problema e introduce las formas para evitarlos y tratarlos. Puedes encontrar aclaraciones adicionales en cualquiera de los textos sobre sistemas operativos.
Resultados¶
Evalúa lo que has aprendido con este test de autoevaluación. Repasa los conceptos en función de los resultados obtenidos.
